Ganze Websites durchsuchen mit der /crawl-API von Cloudflare: So crawlen Sie Seiten, Inhalte und Links schnell und effizient – perfekt für Entwickler.
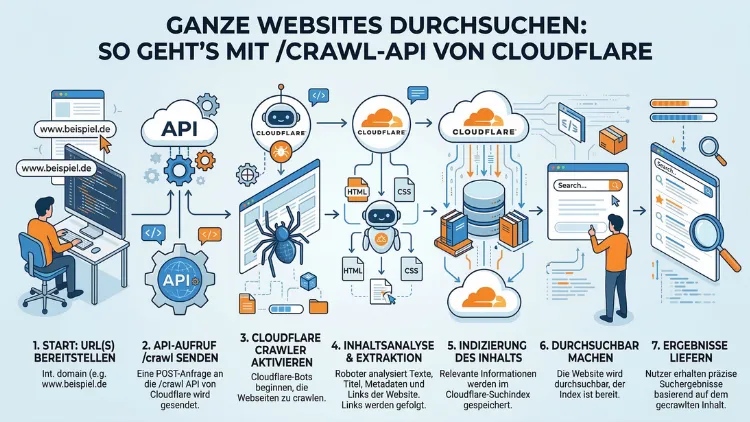
Mit dem neuen /crawl-Endpunkt von Cloudflare Browser Rendering lassen sich ganze Websites per einzelnem API-Aufruf automatisch crawlen – inklusive automatischer Seitenentdeckung, Headless-Browser-Rendering und Ausgabe als HTML, Markdown oder strukturiertes JSON.
Dieser Artikel zeigt Ihnen Schritt für Schritt, wie Sie die API einrichten, welche Parameter entscheidend sind und wann der Einsatz wirklich sinnvoll ist.
Was ist der /crawl-Endpunkt von Cloudflare?
Viele Entwickler verlassen sich bisher auf fragile eigene Skripte, die regelmäßig brechen, oder auf Headless-Browser, die enorme Mengen an RAM verbrauchen. Genau an diesem Punkt setzt Cloudflare an. Der /crawl-Endpunkt durchsucht Inhalte ab einer Start-URL und folgt dabei Links quer durch die gesamte Website – bis zu einer konfigurierbaren Tiefe oder Seitenanzahl.
Technisch gesehen ist der Endpunkt Teil von Cloudflare Browser Rendering, dem Dienst, der bisher vor allem für das serverseitige Rendern von Webseiten bekannt war. Jedoch erweitert Cloudflare diesen Dienst nun erheblich: Der /crawl-Endpunkt läuft auf der Browser Rendering-Infrastruktur von Cloudflare, die Headless-Chrome-Instanzen über das globale Edge-Netzwerk hochfährt.
Der Vorteil gegenüber klassischen Lösungen ist erheblich. Statt Playwright oder Puppeteer selbst zu verwalten, Browser-Instanzen zu skalieren und mit Paginierung zu kämpfen, übernimmt Cloudflare den gesamten Prozess. Kein Browser-Management, keine eigenen Skripte, keine Infrastruktur, die betreut werden muss – lediglich zwei API-Anfragen bilden den gesamten Arbeitsablauf.
Veröffentlicht wurde der Endpunkt am 10. März 2026 und befindet sich derzeit in der Open Beta. Der Ankündigungstweet von @CloudflareDev überschritt innerhalb von 24 Stunden 2 Millionen Impressionen, was den Nerv der Entwickler-Community traf.
Voraussetzungen und Einrichtung
Bevor Sie den ersten Crawl starten, müssen einige Vorbereitungen getroffen werden. Zunächst benötigen Sie ein Cloudflare-Konto – entweder im kostenlosen Workers Free Plan oder im kostenpflichtigen Workers Paid Plan. Außerdem ist ein benutzerdefinierter API-Token mit der Berechtigung „Browser Rendering – Edit“ erforderlich.
Schritt 1: API-Token erstellen
So erstellen Sie den notwendigen Token:
- Melden Sie sich unter dash.cloudflare.com an.
- Navigieren Sie zu Mein Profil → API-Tokens → Token erstellen.
- Wählen Sie die Vorlage „Benutzerdefinierter Token“.
- Vergeben Sie die Berechtigung „Browser Rendering – Edit“.
- Speichern Sie den Token sicher – er wird nur einmal angezeigt.
Zudem benötigen Sie Ihre Account-ID, die Sie im Cloudflare-Dashboard unter dem jeweiligen Konto finden.
Schritt 2: Den Crawl starten (POST-Anfrage)
Sie senden eine POST-Anfrage mit einer URL, um einen Crawl-Job zu starten. Die API antwortet sofort mit einer Job-ID, über die Sie die Ergebnisse später abrufen.
Das folgende Beispiel zeigt die grundlegende Anfrage mit cURL:
curl -X POST 'https://api.cloudflare.com/client/v4/accounts/{account_id}/browser-rendering/crawl' \
-H 'Authorization: Bearer <apiToken>' \
-H 'Content-Type: application/json' \
-d '{
"url": "https://example.com/"
}'Die Antwort enthält unmittelbar eine job_id, zum Beispiel:
{
"jobId": "c7f8s2d9-a8e7-4b6e-8e4d-3d4a1b2c3f4e"
}Schritt 3: Ergebnisse abrufen (GET-Anfrage)
Da Crawls asynchron ausgeführt werden, müssen Sie den Status regelmäßig abfragen. Die möglichen Job-Statuswerte sind: „running“ für laufende Jobs, „cancelled_due_to_timeout“ wenn der Job das Maximum von sieben Tagen überschreitet, „cancelled_due_to_limits“ bei Erreichen von Kontolimits sowie „cancelled_by_user“ bei manuell gestoppten Jobs.
curl -X GET 'https://api.cloudflare.com/client/v4/accounts/{account_id}/browser-rendering/crawl/c7f8s2d9-a8e7-4b6e-8e4d-3d4a1b2c3f4e' \
-H 'Authorization: Bearer <apiToken>'Sobald der Status auf „done“ wechselt, stehen alle gecrawlten Inhalte im gewählten Format bereit.
Alle wichtigen Parameter im Überblick
Der /crawl-Endpunkt bietet zahlreiche optionale Parameter, mit denen Sie den Crawl-Prozess präzise steuern. Deshalb lohnt es sich, diese Parameter gut zu kennen.
Ausgabeformate: HTML, Markdown und JSON
Der Endpunkt unterstützt mehrere Ausgabeformate: HTML, Markdown sowie strukturiertes JSON, das durch Workers AI verarbeitet wird.
format: "html"– Liefert den vollständigen HTML-Quelltext jeder Seite. Nützlich für eigene Parser oder tiefgehende Analysen.format: "markdown"– Konvertiert den Seiteninhalt automatisch in sauberes Markdown. Ideal für KI-Anwendungen und Sprachmodelle.format: "json"– Extrahiert strukturierte Daten mithilfe von Workers AI. Besonders hilfreich für Produktdaten, Preise oder andere semantische Inhalte.
Crawl-Tiefe und Seitenlimit steuern
Der Endpunkt erlaubt Seitenanzahlen von bis zu 100.000, sowie URL-Muster-Abgleich für die Inklusion oder Exklusion bestimmter Pfade.
{
"url": "https://example.com/",
"maxDepth": 3,
"limit": 500
}Zudem ist der Parameter includePattern und excludePattern besonders praktisch, um etwa nur den /blog/-Bereich zu crawlen oder bestimmte Verzeichnisse auszuschließen:
{
"url": "https://example.com/",
"includePattern": "/docs/*",
"excludePattern": "/admin/*"
}Statischer Modus: Schneller crawlen ohne Browser
Im statischen Modus lässt sich render: false setzen, um statisches HTML ohne Hochfahren eines Browsers abzurufen – für deutlich schnelleres Crawlen statischer Seiten.
{
"url": "https://example.com/",
"render": false
}Dieser Modus ist während der Beta kostenlos und eignet sich für alle Seiten, die kein JavaScript-Rendering benötigen.
Inkrementelles Crawlen: Nur geänderte Seiten neu laden
Durch die Parameter modifiedSince und maxAge lassen sich beim inkrementellen Crawlen Seiten überspringen, die sich nicht geändert haben oder erst kürzlich abgerufen wurden – was Zeit und Kosten bei wiederholten Crawls spart.
{
"url": "https://example.com/",
"modifiedSince": "2026-02-01T00:00:00Z",
"maxAge": 86400
}Ebenso nützlich ist der Parameter rejectResourceTypes, mit dem unnötige Ressourcen wie Bilder, Medien oder Schriftarten blockiert werden können, um den Crawl-Prozess zu beschleunigen.
Seitenentdeckung: Wie der Crawler URLs findet
Der Crawler entdeckt und verarbeitet URLs in folgender Reihenfolge: zunächst die Start-URL, dann Sitemap-Links aus der Sitemap der Website und schließlich Links von bereits besuchten Seiten.
Standardmäßig verwendet der Parameter source: "all" beide Methoden. Alternativ lässt sich source: "sitemap" für ausschließliches Sitemap-Crawling oder source: "links" für reine Link-Verfolgung setzen. Außerdem besteht die Möglichkeit, mit includeExternalLinks: true auch externe Verlinkungen zu folgen, was beispielsweise für umfangreiche Wettbewerbsanalysen interessant ist.
Preisgestaltung: Was kostet der /crawl-Endpunkt?
Crawls mit render: false sind während der Beta kostenlos und werden danach nach dem Standard-Workers-Preis abgerechnet. Crawl-Jobs haben eine maximale Laufzeit von 7 Tagen, und die Ergebnisse bleiben 14 Tage lang verfügbar.
Für den kostenpflichtigen Modus mit Headless-Rendering gilt folgende Kalkulation: Mit dem Paid-Plan für 5 US-Dollar pro Monat sind 10 Stunden Browser-Rendering-Zeit enthalten. Wenn ein 100-seitiger Crawl etwa 5 Minuten Browser-Zeit benötigt, lassen sich damit rund 12.000 Seiten pro Monat für 5 Dollar crawlen.
Im direkten Vergleich mit Wettbewerbern ist das äußerst attraktiv. Der Standard-Plan von Firecrawl kostet 47 US-Dollar pro Monat für 100.000 Seiten, während Cloudflare bei entsprechendem Volumen deutlich günstiger abschneidet – vor allem für Teams, die bereits im Cloudflare-Ökosystem arbeiten.
Anwendungsfälle: Wofür eignet sich der /crawl-Endpunkt?
KI-Training und RAG-Pipelines
Der naheliegendste Anwendungsfall ist der Aufbau von Wissensbasen für RAG-Systeme. Damit lässt sich eine gesamte Produktdokumentations-Website in Markdown einlesen, in Chunks aufteilen, vektorisieren und in einen Index einpflegen, damit KI-Agenten präzise antworten.
Inhaltsmonitoring und Wettbewerbsanalyse
Unternehmen können den Endpunkt nutzen, um regelmäßig Änderungen auf Wettbewerber-Websites zu überwachen. Durch inkrementelles Crawlen mit modifiedSince werden dabei nur tatsächlich geänderte Seiten neu abgerufen, was Kosten erheblich reduziert.
Technisches SEO und Site-Audits
Entwickler können den /crawl-Endpunkt in CI/CD-Pipelines integrieren und automatisch nach jedem Deployment einen Crawl anstoßen, der auf fehlende Meta-Tags, kaputte Links oder Weiterleitungsfehler prüft.
Produktdaten-Extraktion mit strukturiertem JSON
Mit dem JSON-Format lassen sich strukturierte Produktdaten extrahieren – etwa Produktname, Preis und Beschreibung aus einem bestimmten Seitenbereich. Dazu kann ein eigener Prompt mitgegeben werden:
{
"url": "https://shop.example.com/products",
"format": "json",
"jsonPrompt": "Extrahiere Produktname, Preis und Beschreibung aus dem Produktbereich der Seite."
}Compliance und robots.txt: Verhält sich der Crawler regelkonform?
Eine häufige Sorge bei Crawling-Tools ist die Frage der Compliance. Der /crawl-Endpunkt ist ein signierter Agent, der robots.txt und AI Crawl Control standardmäßig respektiert – also eine klare Option für Entwickler, die sich an Website-Regeln halten wollen, und es weniger wahrscheinlich macht, dass Crawler die Vorgaben der Website-Betreiber ignorieren.
Zudem identifiziert sich der Crawler ausdrücklich als Bot und umgeht keine Anti-Bot-Mechanismen. Wenn ein Website-Betreiber Bots blockiert, schlägt der Crawl fehl – das gibt Inhaltseignern die Kontrolle.
Dieser Ansatz unterscheidet Cloudflare deutlich von anderen Crawlern, die versuchen, sich als menschliche Browser zu tarnen. Deshalb ist der Endpunkt aus rechtlicher und ethischer Sicht klar positioniert.
Häufige Fehler und empfohlene Vorgehensweisen
Problem: „cancelled_due_to_limits“
Dieser Status bedeutet, dass das Konto sein Browser-Zeitlimit erreicht hat. Accounts im Workers-Free-Plan sind auf 10 Minuten Browser-Nutzung pro Tag begrenzt.
Lösungen:
- Upgrade auf den Workers Paid Plan
render: falsefür statische Inhalte verwendenmaxAgeerhöhen, um gecachte Ergebnisse zu nutzenlimitreduzieren und mehrere kleinere Crawls ausführen
Problem: Langsames Crawlen durch Ressourcen
Zusätzlich sollten unnötige Ressourcen blockiert werden. Der Parameter rejectResourceTypes kann Bilder, Medien und Schriftarten herausfiltern:
{
"url": "https://example.com/",
"rejectResourceTypes":
}Empfohlene Vorgehensweise für JSON-Extraktion
Für eine gute JSON-Extraktion ist ein klarer Prompt entscheidend: Geben Sie genau an, welche Daten extrahiert werden sollen und wo sie auf der Seite erscheinen.
Vergleich mit alternativen Crawling-Lösungen
Neben Cloudflare gibt es weitere nennenswerte Tools für das Web-Crawling:
Firecrawl ist ein spezialisierter Crawling-Dienst mit umfangreichen Optionen. Jedoch ist er deutlich teurer und erfordert eine externe Abhängigkeit. Für Teams, die bereits Cloudflare nutzen, ist der Mehrwert eines separaten Dienstes fraglich.
Jina Reader (r.jina.ai) ist ideal für die schnelle Konvertierung einzelner Seiten in LLM-freundliches Markdown. Jina Reader ist für einzelne Seiten-Konvertierungen perfekt, bietet aber keinen nativen Multi-Seiten-Crawl.
Playwright/Puppeteer bieten maximale Kontrolle, erfordern jedoch eigene Infrastruktur, Skalierung und Wartung. Außerdem sind sie für einfache Content-Extraktion häufig überdimensioniert.
Scrapy (Python) ist ein leistungsstarkes Open-Source-Framework für komplexe Crawling-Projekte. Jedoch ist die Lernkurve steil und der Betrieb aufwendig.
Cloudflares /crawl-Endpunkt positioniert sich deshalb als pragmatische Mitte: einfach genug für schnelle Projekte, aber mächtig genug für großangelegte Datenextraktionen.
Integration in bestehende Workflows
Node.js-Integration
Für Node.js-Projekte empfiehlt sich die Verwendung von fetch oder axios:
const startCrawl = async (url, accountId, apiToken) => {
const response = await fetch(
`https://api.cloudflare.com/client/v4/accounts/${accountId}/browser-rendering/crawl`,
{
method: 'POST',
headers: {
'Authorization': `Bearer ${apiToken}`,
'Content-Type': 'application/json',
},
body: JSON.stringify({
url,
format: 'markdown',
maxDepth: 3,
limit: 100,
render: false,
}),
}
);
const data = await response.json;
return data.jobId;
};Python-Integration
Ebenso lässt sich die API problemlos aus Python aufrufen:
import requests
def start_crawl(url, account_id, api_token):
endpoint = f"https://api.cloudflare.com/client/v4/accounts/{account_id}/browser-rendering/crawl"
headers = {
"Authorization": f"Bearer {api_token}",
"Content-Type": "application/json"
}
payload = {
"url": url,
"format": "markdown",
"maxDepth": 3,
"limit": 200,
"render": False
}
response = requests.post(endpoint, json=payload, headers=headers)
return response.json.get("jobId")In CI/CD-Pipelines integrieren
Für automatisierte Workflows eignet sich ein einfaches Skript, das nach einem Deployment automatisch einen Crawl anstößt. Dabei sollte jedoch darauf geachtet werden, render: false zu verwenden, um das tägliche Browser-Zeitlimit nicht unnötig zu verbrauchen.
Grenzen und Einschränkungen des /crawl-Endpunkts
Trotz aller Vorteile gibt es einige wichtige Einschränkungen, die Sie kennen sollten:
Zunächst ist der Endpunkt nicht in der Lage, Cloudflare-eigene Bot-Erkennung zu umgehen. Der /crawl-Endpunkt kann keine Cloudflare-Bot-Erkennung oder Captchas umgehen und identifiziert sich selbst als Bot. Folglich schlägt ein Crawl auf Seiten fehl, die aggressiven Bot-Schutz verwenden.
Außerdem unterliegen Sites mit strengen Rate-Limits naturgemäß einem langsameren Crawling. Der Crawler respektiert zwar Crawl-delay aus der robots.txt, jedoch kann es bei sehr langsamen Seiten zu erheblichen Verzögerungen kommen.
Zudem sollten Sie beachten, dass Authentifizierung möglich, aber aufwendig ist. Gesperrte Bereiche hinter Login-Formularen erfordern das manuelle Setzen von Cookies oder HTTP-Authentifizierungsdaten.
